Film Logging and Recommendation Streamlit App
Introduction
A simple film score logging app using Streamlit. Collected data, such as director, genre, and scores are then used to build a personalised film recommendation system. Visualisations are compiled using vega lit for interactive visualisations. Codes can be found in this GitHub Repo.
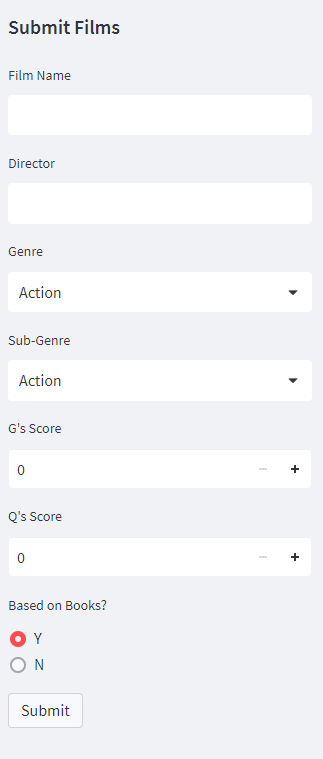
Submitting Films
Film scores can be submitted using the side-bar form. Required information are file name, director, genre, sub-genre, scores, and if the film is based on books. The data is stored using Google Sheet and hooked to Streamlit.
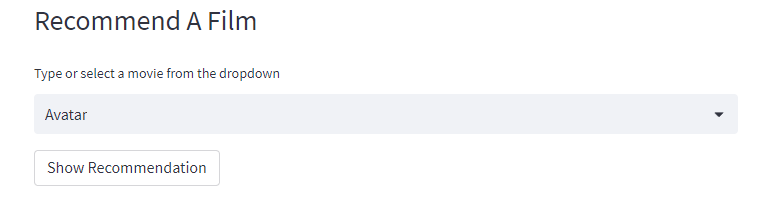
Personalised Film Recommendation
Using the data collected, a film recommendation system is built in to recommend films based on our preference. Similarity score is calculated using cosine similarity.
def recommend(movie):
# find the index of the movies
movie_index = new_df[new_df['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)), reverse=True, key=lambda x: x[1])[1:6]
# to fetch movies from indeces
for i in movies_list:
print(new_df.iloc[i[0]].title)
Visualisations
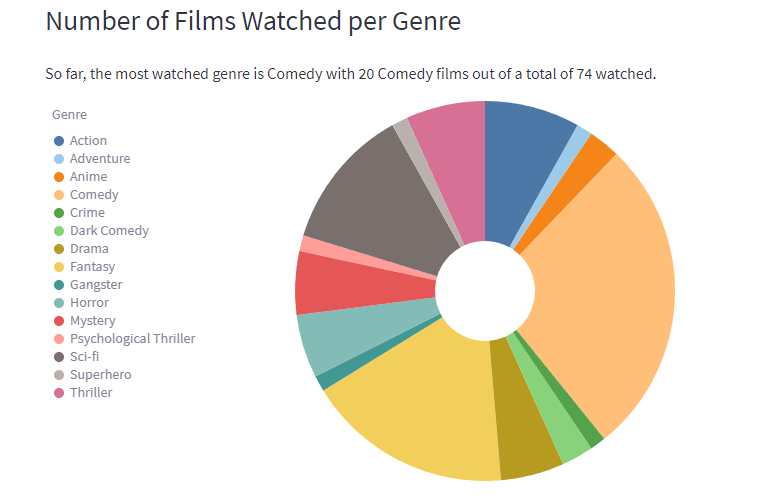
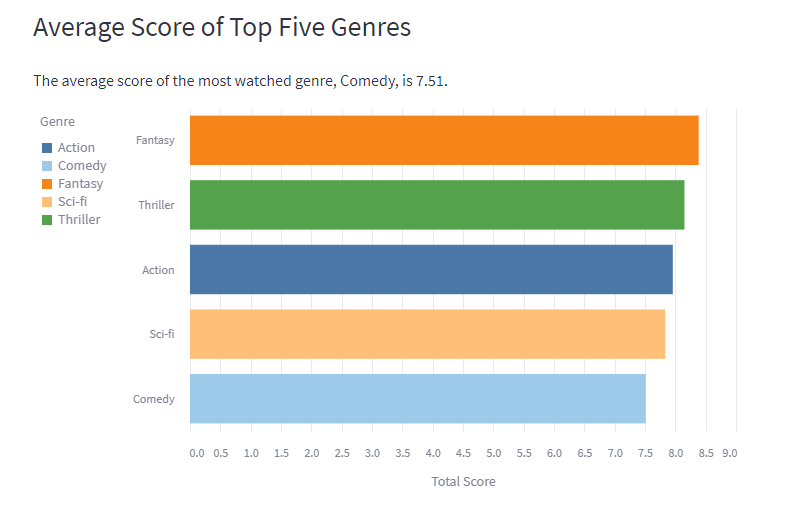
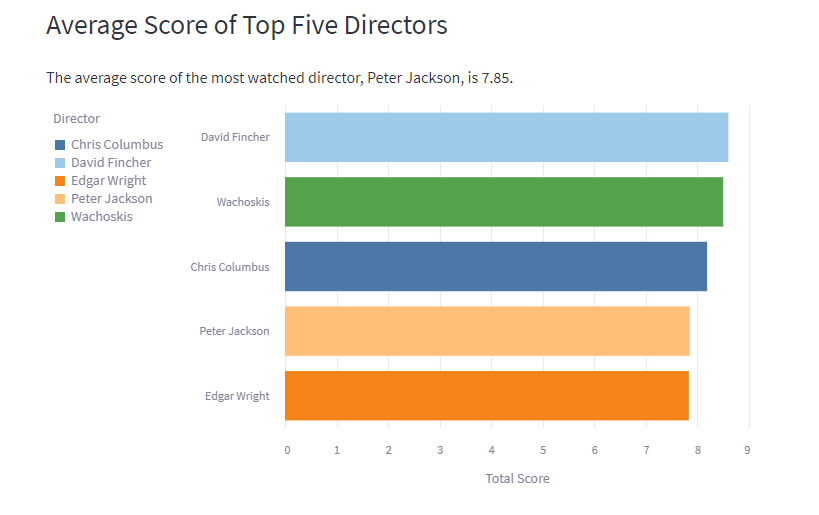
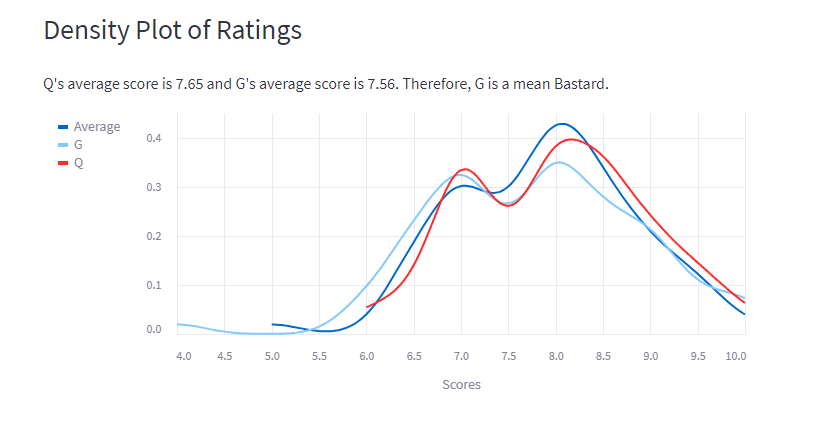
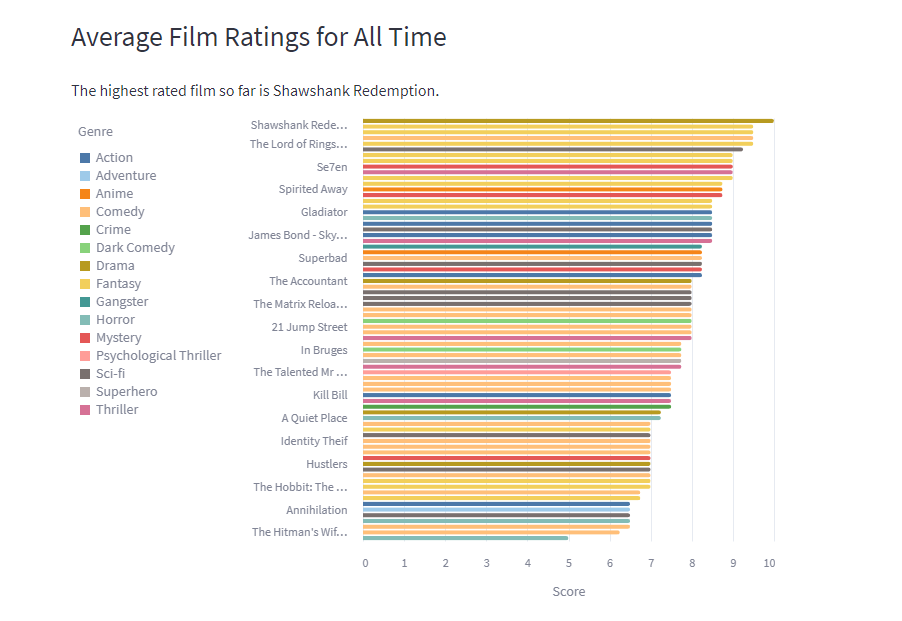
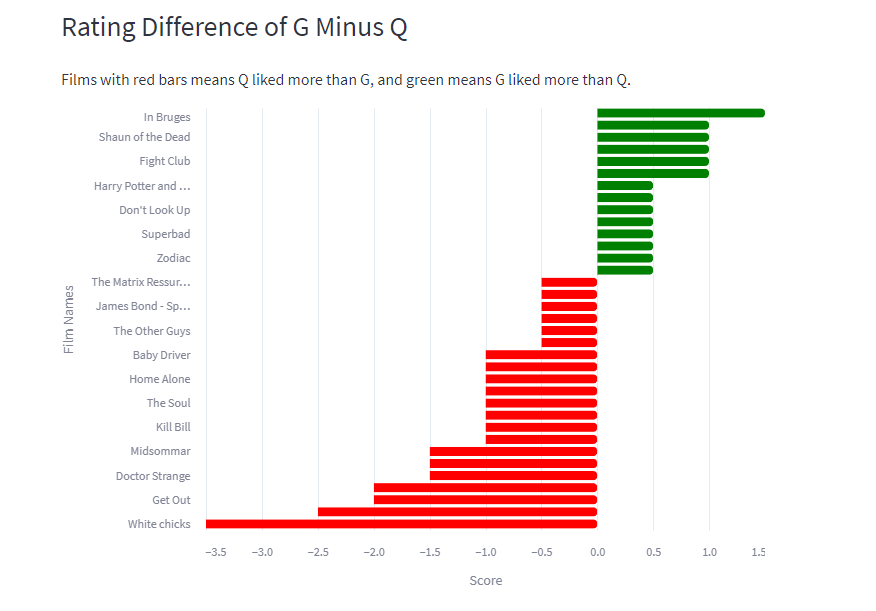
All visualisations are interactive as they are built using vega lite. So our most watched genre so far is fantasy, and it also has the highest average score. Director with the highest average score is David Fincher, no surprise there as he directed films like Fight Club, Seven, and Gone Girl. The density plot shows that I tend score films higher than G, but we have a similar trend of scoring films. Our highest rated film so far is Shawshank Redemption, and least rated is Boston Strangler (sorry Keira). The rating difference graph shows that G prefers In Bruges way more than me, whereas I liked Spirited Away more than G.