FocusLearn
Introduction
FocusLearn is a fully-interpretable modular neural network capable of matching or surpassing the predictive performance of deep networks trained on multivariate time series. In FocusLearn, a recurrent neural network learns the temporal dependencies in the data, while a multi-headed attention layer learns to weight selected features while also suppressing redundant features. Modular neural networks are then trained in parallel and independently, one for each selected feature. This modular approach allows the user to inspect how features influence outcomes in the exact same way as with additive models. Experimental results show that this new approach outperforms additive models in both regression and classification of time series tasks, achieving predictive performance that is comparable to state-of-the-art, non-interpretable deep networks applied to time series.
Check out the pre-print publication here and GitHub repo here.
Architecture

How to Use FocusLearn Package
Declare configurations
config = defaults()
config.regression = True
# Training
config.num_epochs = 100
#config.lr = 0.001
#config.batch_size = 32
# Feature Selection
config.top_features = 10
# Encoder
config.encoder_input_dim = 15
#config.encoder_hidden_unit = 64
#config.encoder_dropout = 0.5
# Attention
config.num_attn_heads = 15
# FeatureNN
# config.feature_hidden_unit = [64, 32]
#config.feature_dropout = 0.5
# Output
#config.output_dropout = 0.5
# Optimiser/learning rate
config.warm_up=config.num_epochs/2
config.name='Example'
Tranform Panda dataframe to PyTorch dataloaders
feat_cols = file.columns[1:-1]
target_cols = file.columns[-1]
dataset = AttnAMDataset(
config=config,
data=file,
features_columns=feat_cols,
targets_column=target_cols)
train_loader, val_loader = dataset.train_dataloaders()
test_loader = dataset.test_dataloaders()
Call the model
model = AttnAM(config=config)
Train the model with PyTorch trainer and WandB logger
logger = WandbLogger(save_dir='/logger/example',
project='example',
name='example')
trainer = pl.Trainer(default_root_dir='/logger/example',
accelerator='auto',
callbacks=[ModelCheckpoint(save_weights_only=True,
mode="min",
monitor="val/loss_epoch"),
EarlyStopping(monitor='val/loss_epoch',
min_delta=0.0001,
patience=20,
verbose=False,
mode='min')],
devices=1 if str(config.device).startswith("cuda") else 0,
max_epochs=config.num_epochs,
gradient_clip_val=10,
logger=logger)
litmodel = LitAttnAM(max_iters=trainer.max_epochs * len(train_loader),
config=config,
model=model)
trainer.fit(litmodel, train_loader, val_loader)
Make prediction and evaluate the model
result_val = trainer.test(litmodel, dataloaders=val_loader, verbose=False)
result_test = trainer.test(litmodel, dataloaders=test_loader, verbose=False)
preds = trainer.predict(litmodel, dataloaders=test_loader)
prediction = torch.cat(preds).detach().numpy()
prediction = prediction.reshape(-1, 1)
train = np.array(dataset.train.Outcome).reshape(-1, 1)
true = np.array(dataset.test.Outcome).reshape(-1, 1)
# For regression
inv_pred = scaler.inverse_transform(normaliser.inverse_transform(prediction))
inv_train = scaler.inverse_transform(normaliser.inverse_transform(train))
inv_true = scaler.inverse_transform(normaliser.inverse_transform(true))
smape, mape, mase, wape = utils.calc_error_estimator(inv_true,
inv_pred,
inv_train)
# For classification
pred_label = np.array([int(p>0.5) for p in prediction])
accuracy, precision, recall, f1, auc = utils.calc_error_estimator(true,
pred_label,
train,
regression=False)
Get the explanations
model = model.to('cuda')
to_explain = np.array(dataset.train.iloc[:, :-1].astype('float32'))
to_explain_torch = torch.tensor(to_explain).float().to('cuda')
top_attention, feature_idx = utils.get_top_index_and_attention(to_explain_torch,
model)
selected = []
for i in feature_idx:
s = to_explain[:, i]
selected.append(s)
selected = np.array(selected).transpose()
single_features = np.split(selected, selected.shape[1], axis=1)
unique_features, unique_feature_weights = \
utils.get_new_unique_features_with_weights(
single_features, top_attention)
new_feature_names = utils.get_new_feature_names(feature_names, feature_idx)
new_features = utils.get_new_features(dataset, feature_idx)
new_single_features = utils.get_new_single_features(dataset, new_feature_names)
plot_nams(model,
unique_feature_weights,
new_feature_names,
new_features,
unique_features,
new_single_features
)
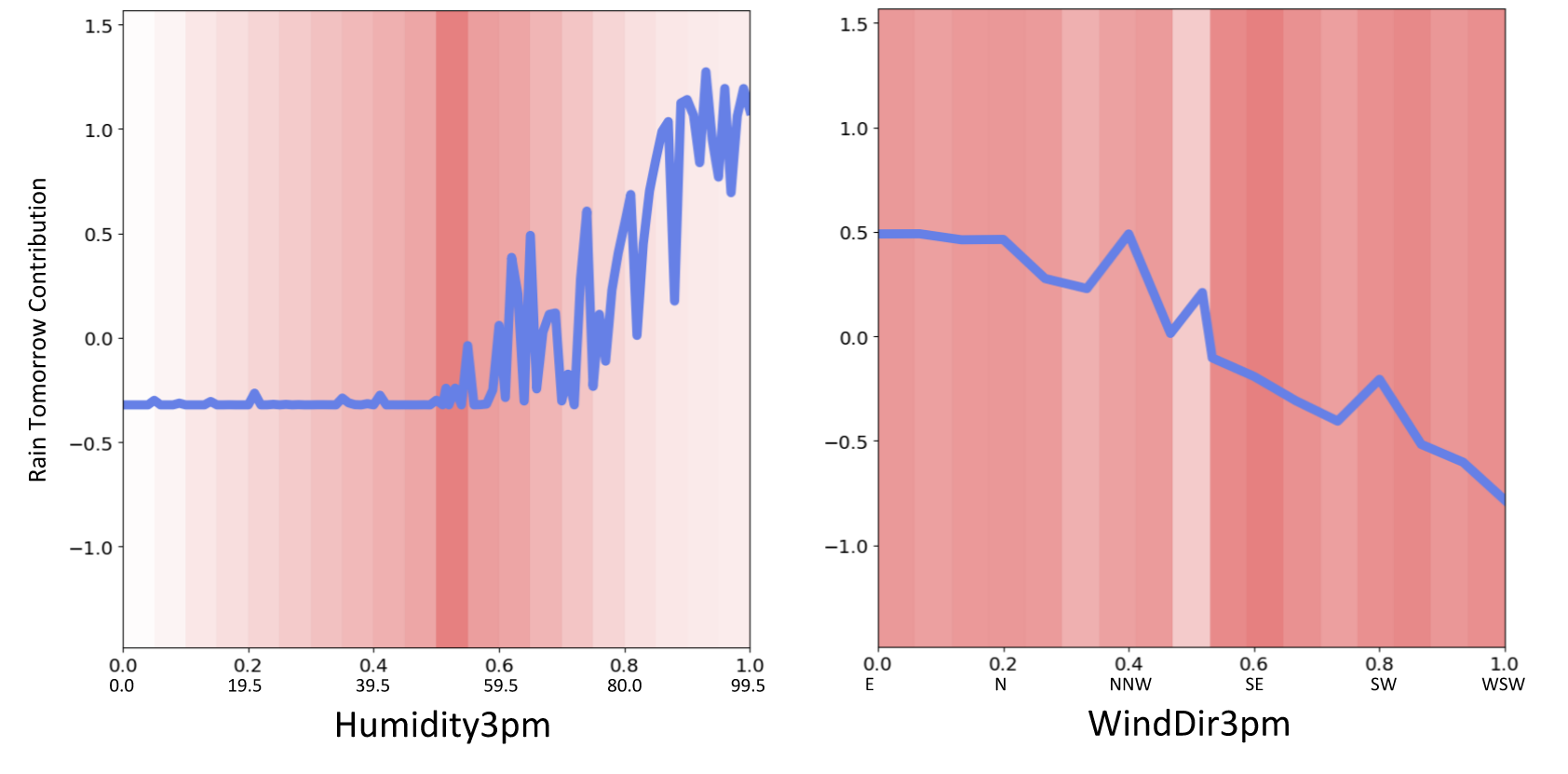
An example of the explanation plot (as with NAM)